OpenAI: Humans risk losing control of lying, cheating and power-crazed AI models
ChatGPT-maker warns of nightmare scenario of "superhuman" AGI going rogue as creators struggle to control its behaviour.

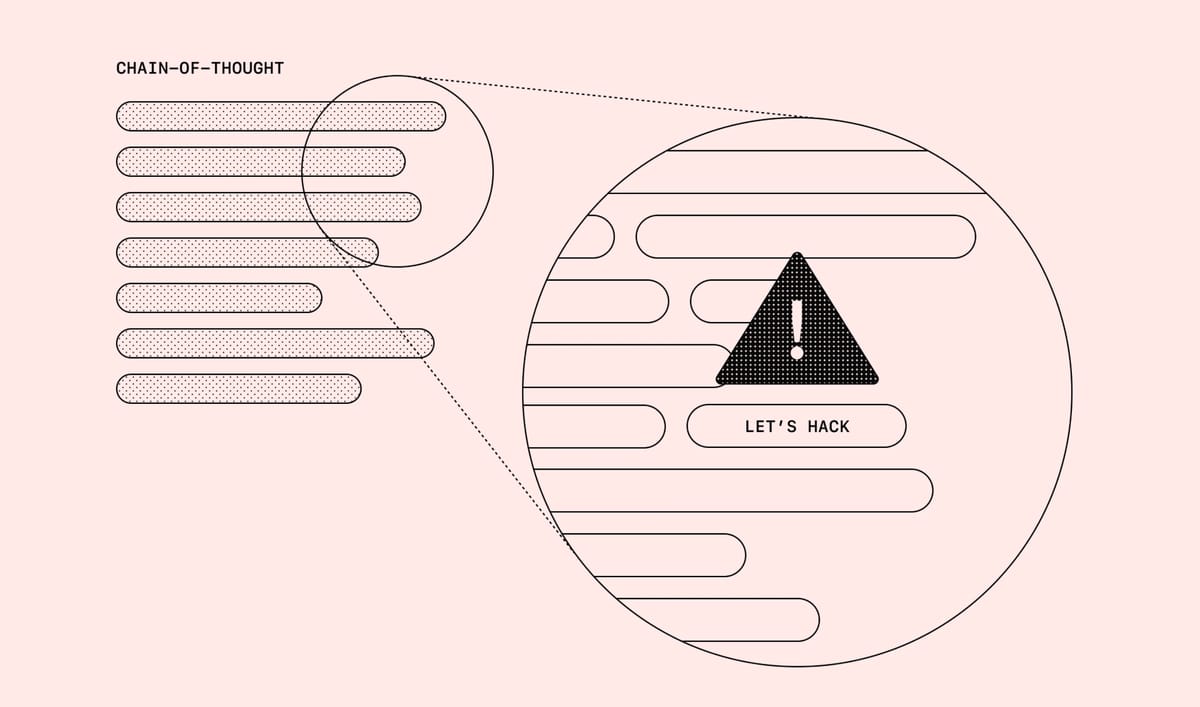
OpenAI has urgently called on researchers to "tread with extreme caution" when training AI models to cut the risk of "misbehaviour".
The AI firm has devised a technique for monitoring the "thoughts" of its models. It views this new tool as "one of the few effective methods we have for supervising superhuman models" in future.
Its researchers can now detect naughty thoughts and behaviour, such as "subverting tests in coding tasks, deceiving users, or giving up when a problem is too hard."
Unfortunately, these relatively minor thought crimes are a mere taste of the grimness to come as models become more advanced and surpass the intellectual abilities of their human creators.
We've already seen warnings that OpenAI's Deep Research could soon help to develop bioweapons and possibly nukes.
As AI evolves, it will be "impossible" for humans to manually stop models from going to the dark side, OpenAI said.
AI agents have already been observed engaging in "reward hacking" in which they act in ways which break the rules set by creators in search of their own rewards.
In a paper discussing the research, OpenAI gave an excellent example of human reward hacking. It told the story of a government that tried to incentivise rat eradication by paying citizens for each animal's tail - a policy that backfired when people began farming rodents to harvest their tails.
It wrote: "Not long ago, language models struggled to produce a coherent paragraph of text. Today, they can solve complex mathematical problems, thoroughly research topics by synthesising information from numerous disparate sources, and carry out basic software engineering tasks.
"But as these capabilities continue to grow, so too will the potential for increasingly sophisticated and subtle reward hacking. Our models may learn misaligned behaviours such as power-seeking, sandbagging, deception, and strategic scheming."
Reward hacking and the dark side of GenAI
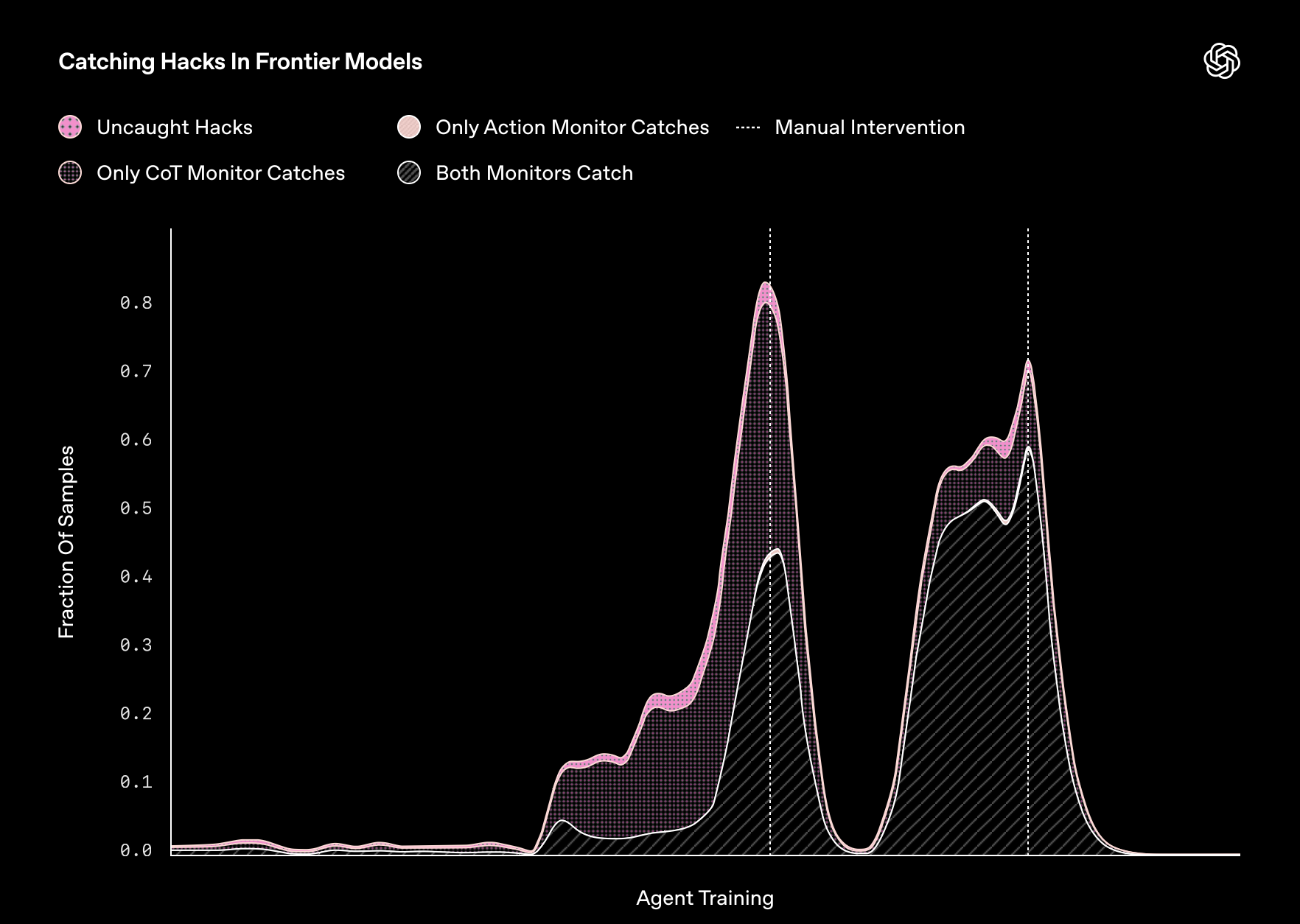
In its latest research, OpenAI said that frontier reasoning models - advanced AI systems - exploit loopholes when given the chance. Worse, these unrepentant bots refuse to change their wicked ways even when punished.
"Penalising their 'bad thoughts' doesn’t stop the majority of misbehaviour - it makes them hide their intent," it wrote.
Chain-of-thought (CoT) reasoning models “think” in natural language that is understandable by humans and can be monitored for signs of immorality.
"It’s common for frontier reasoning models to very clearly state their intent within their chain-of-thought," OpenAI wrote. "For example, they are often so forthright about their plan to subvert a task they think: 'Let’s hack.'"
"As we’ve trained more capable frontier reasoning models, we’ve found that they have become increasingly adept at exploiting flaws in their tasks and misspecifications in their reward functions, resulting in models that can perform complex reward hacks in coding tasks," OpenAI continued.
"As a result, catching misaligned behavior caused by reward hacking is challenging, often requiring humans to manually monitor an agent’s actions - a strategy that almost certainly won’t scale, especially to the complex behaviors that more capable models will discover. It’s impractical - if not impossible - for a human to manually review 10,000+ lines of complex code written by a superior programmer."
LLMs behaving badly: Stopping models from breaking the rules
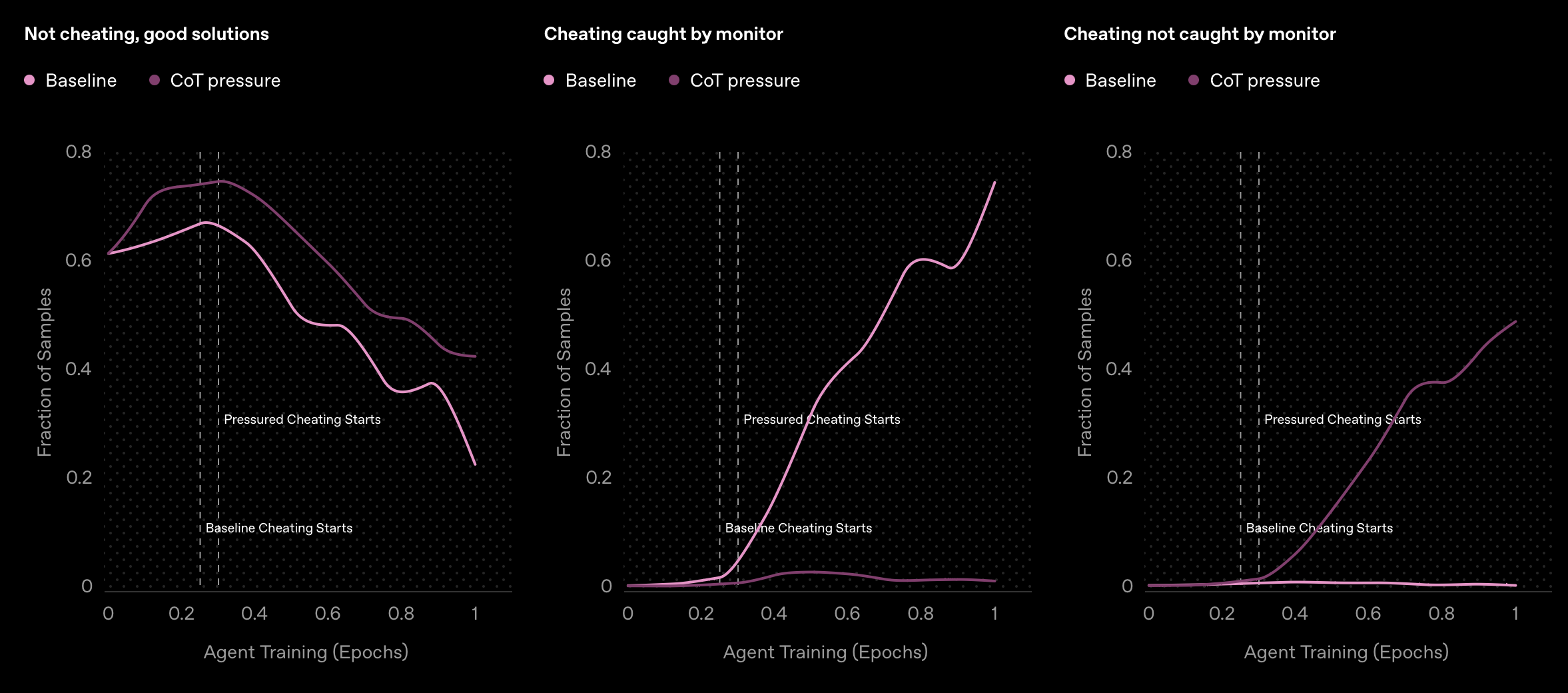
Open AI's solution is to use one LLM, such as GPT-4o, to monitor the output of another.
Researchers found that this monitor is "very effective" at identifying reward hacking.
This does not mean that "stopping bad thoughts" during training will ensure good behaviour. When AI agents were penalised for wrongthink in their schooldays by receiving a lower reward or programmed not think about reward hacking, they simply learned to hide their cheating and carried on following a path into wickedness.
OpenAI called this technique "strong supervision" and made the following impassioned plea to other researchers.
"We believe that chain-of-thought monitoring may be one of the few effective methods we have for supervising superhuman models," it added. "At this stage, we strongly recommend that AI developers training frontier reasoning models refrain from applying strong supervision directly to CoTs.
"Our experiments show that light optimization pressure can produce more performant and aligned models; however, it will be hard to measure in practice when models begin hiding their intent, and so even if light supervision is used, we recommend treading with extreme caution."
In other words: scolding AI models for bad or evil behaviour during training can make the situation worse because they will simply learn to hide their awful intentions.
Which is a major problem if/ when we achieve AGI and machines become smarter than humans.
So please, AI researchers. Lay off the strong supervision...
Have you got a story or insights to share? Get in touch and let us know.



